はじめましてVeeam Softwareの高橋です。
ここでの初めてのブログです。
少しだけ自己紹介をさせていただくと、ハードウェア的なキャリアはたくさんあって、ギネスブックに載っているような大型機から、ワークステーション、ラズパイまで扱ったことがあります。データマネージメント業界では、古くはファイルバックアップの製品、新しめのクラウドでのマネージメントツールなどをやってきました。
さて、今日のお題ですが、バックアップデータをしっかりみてもらうということで、「バックアップの重複排除とバックアップレポジトリを入れたときの見え方の挙動」について書いていきたいと思います。
バックアップの重複排除
仮想マシンや物理マシンをバックアップすると結構な容量になると思います。
もっぱらテンプレートから展開した仮想マシンの場合は、実はOSやアプリケーションの部分が共通なものなので、重複排除が効くのではと思われるかもしれません。
バックアップ時における重複排除について考えてみましょう。以下の2つに分かれるかと思います。
- ファイルコンテンツの重複排除
- イメージレベルの重複排除
1. ファイルコンテンツの重複排除
以下のようなケースで重複排除が起きると思います。
- 同じファイルシステムの中で同じファイルが存在するケース。例えば個々のアプリケーションが参照するダイナミックリンクライブラリが実は同一なものだった
- ディレクトリ構造を維持してファイルコピーでアーカイブをとっていて、多くのファイルが同一ファイルであるケース
2. イメージレベルの重複排除
例えば、同じ仮想マシンテンプレートからクローンした仮想マシンがたくさんある。あるいは、同じOSバージョンの物理マシンのバックアップがある。
いずれにせよ、オンリーワンのデータをしっかり保存して、重複排除をしてバックアップ保存先のデータ消費を少なくしたいと思う人が多いと思います。
Veeamでこれらを検証したいと思います。
Veeamでは、組み込みの重複排除のエンジンが入っています。

このチェックボックスをオン、オフをすることによって重複排除が制御できます。
この設定を利用してテストをしてみたいと思います。
テスト環境は、CentOS 8に /: 16GB OS /data: 100GB /dataには1GBの同一ファイルが10ファイルあります。
1.ファイルコンテンツの重複排除
ファイルコンテンツの重複排除の場合、重複排除が効けば/dataのファイルは1GB程度になると想定できます。
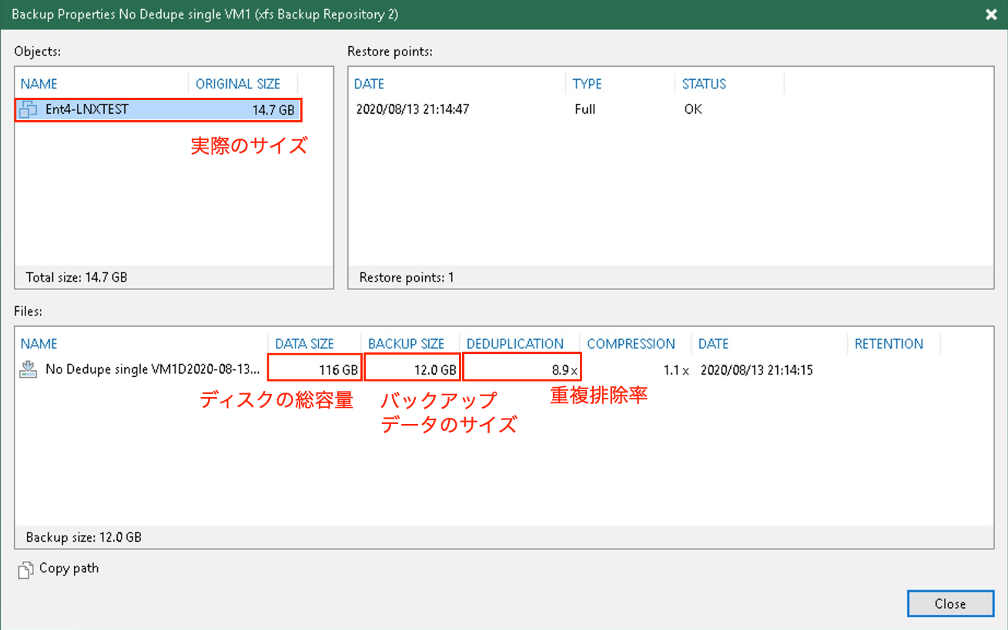
<重複排除オフ>
転送データ量12GB
かかった時間 20:07

実際のサイズ: 14.7GB
バックアップサイズ:12GB
<重複排除オン>
転送データ量12GB
かかった時間 20:42

実際のサイズ: 14.7GB
バックアップサイズ:2.97GB
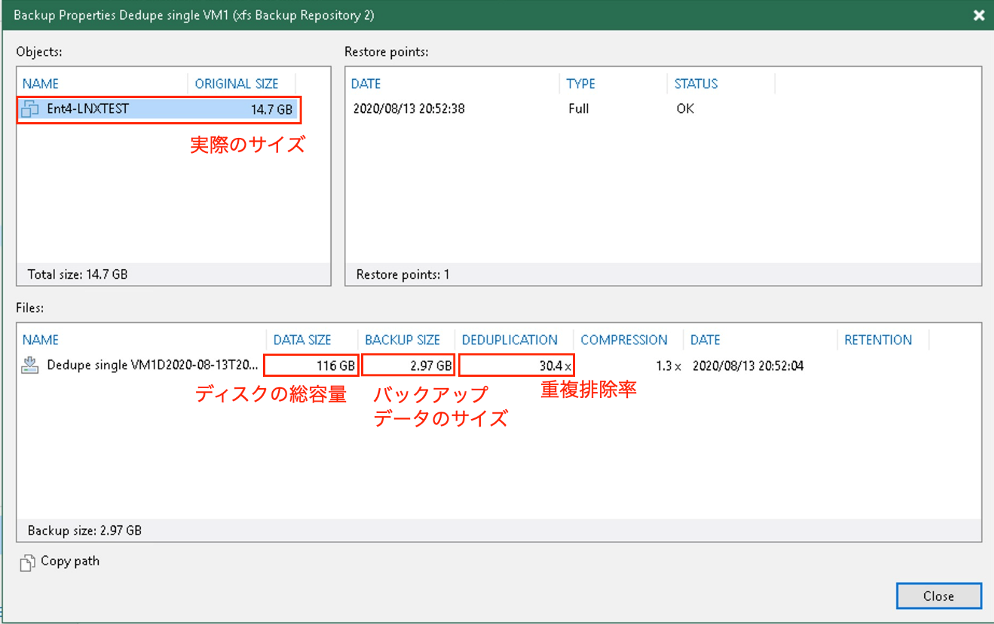
重複排除前:バックアップサイズ:12GB
重複排除後:バックアップサイズ:2.97GB
仮想マシン1台に対してもデータの重複排除が効くことがわかります。
2. イメージレベルの重複排除
仮想マシンのバックアップは、1ジョブに対して1仮想マシンではなく、複数の仮想マシンを指定することができます。
仮想マシンをクローンしたものでテストしてみたいと思います。
この仮想マシンは、同じ仮想マシンをクローンしているのでOSの部分が重複排除されるはずなので、4仮想マシン対象で実質1仮想マシン分程度しか消費しないと推測されます。
この場合の重複排除は、以下のように、1つのジョブに複数の仮想マシンを登録すると重複排除が効きます。重複排除を効果的に効かせるには
– 同じテンプレートから展開されたもの
– 同じOS
– 同じイメージサイズ
ということが重要です。また、通常のレポジトリだと1つのジョブに30仮想マシン以内にすることをお勧めします。


バックアップレポジトリを入れたときの
見え方の挙動
次に、バックアップレポジトリの形式についてです。
バックアップレポジトリとは、バックアップデータを保存しておくためのストレージです。
サポートしているストレージは主に以下のようなバックアップレポジトリがあります。

先ほどの4仮想マシンを1つのジョブでバックアップしたバックアップレポジトリの中身は以下のようになっています。
4つの仮想マシンをバックアップしているのですが、バックアップの実態は1つのファイルです。

このファイルはフルバックアップのファイルで、以後、増分バックアップのファイルが1つづつ増えていきます。
このように、4つの仮想マシンが1つのバックアップファイルになっています。
バックアップレポジトリには主に2つの形式があります。
– 通常のバックアップレポジトリ
– Per-VMバックアップレポジトリ
通常のバックアップレポジトリは、ジョブ単位でバックアップファイルが作成されます。
Per-VMバックアップレポジトリは、仮想マシン単位でバックアップファイルが作成されます。
Per-VMバックアップレポジトリの設定は、バックアップレポジトリの設定でRepository → Advanced 設定で行うことができます。
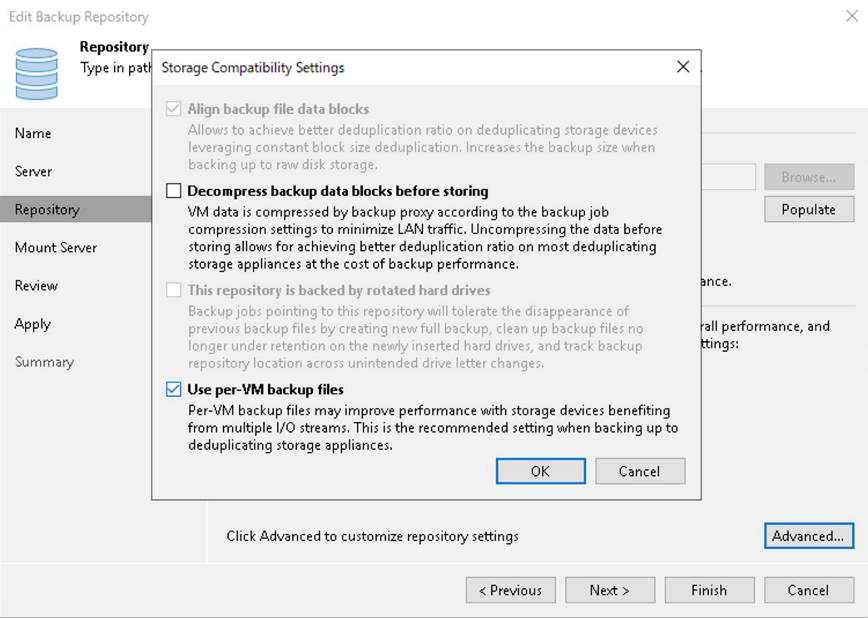
PerーVMバックアップレポジトリは、仮想マシンのバックアップを複数同時に扱うことができるのでバックアップパフォーマンスが向上します。反面、仮想マシン単位なので、生成されるバックアップファイルは多くなります。
以下がPer-VMバックアップレポジトリでバックアップした場合のケースです。

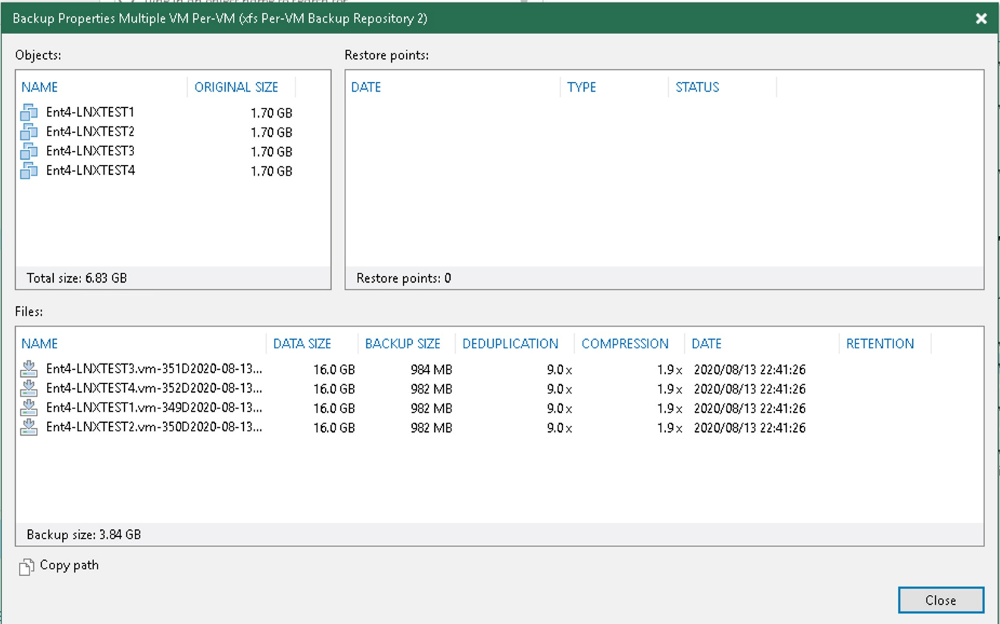

仮想マシン分のファイルが生成されているのがわかると思います。
もう一度、通常のバックアップレポジトリと照らし合わせてみると、Per-VMバックアップレポジトリの方が必要とするバックアップデータ量が多いことがわかります。

さて、このPer-VMバックアップレポジトリは何のためにあるのでしょうか?
このPer-VMバックアップレポジトリは、ストレージ側で重複排除をする場合に有効となります。
つまり、仮想マシンごとのファイルでストレージ側で重複排除が有効的にできるようになります。
よって、バックアップレポジトリとして重複排除ストレージを利用する場合、バックアップレポジトリの設定をPer-VMバックアップレポジトリにするのが一般的です。
また、その場合は、Veeamの重複排除をオフに設定する必要があります。重複排除は、Veeamで行うか、ストレージで行うかはトレードオフです。
Per-VMレポジトリは、重複排除レポジトリだけではなく、スケールアウトバックアップレポジトリの場合は、自動的に有効になります。
スケールアウトバックアップレポジトリとは、複数のバックアップレポジトリを1つに束ねたり、Cloud Tierとしてオブジェクトストレージを利用する場合に使います。Per-VMの設定が有効になると、スケールアウトバックアップレポジトリで構成されているバックアップレポジトリが個々でバックアップタスクを受け取ることができ、また、細かくファイルを配置ができるのでストレージを有効活用することが可能になります。
バックアップレポジトリの設定でバックアップファイル自体で効率化するか、ストレージの機能を有効活用するかはやはりトレードオフになります。
また、このPer-VMバックアップレポジトリは、1つのジョブで300仮想マシン程度を指定することができます。重複排除ストレージと連携させるなどの大規模環境で利用すると便利な設定です。
まとめ
今回、Veeamの重複排除の機能を実際のバックアップジョブで確かめてみました。環境によっては、1仮想マシン、1ジョブで設定されているケースもありますが、OSやサイズが一緒のものであれば、複数仮想マシンを1ジョブで設定することをお勧めします。単体の仮想マシンのバックアップがしたいという場合は、Quick Backupという機能を使うことで単体の仮想マシンのバックアップも可能です。Quick Backupはいずれお話ししたいと思います。
また、レポジトリ形式でジョブ単位でバックアップファイルが生成できる、Per-VMバックアップレポジトリで、仮想マシン単位でバックアップファイルが生成できることを説明しました。状況に応じて使い分けて効率化をすることをお勧めします。
関連するその他の製品・ソリューションはこちら
Microsoft 365のデータの包括的なバックアップをサポートする「Veeam Backup for Microsoft Office 365」。製品概要や利用シーン、成功事例はこちら。
Windowsベースのシステム、物理サーバー、クラウドインスタンス向けの包括的なバックアップおよび復元ソリューション「Agent for Microsoft Windows」。製品概要やエディション比較、成功事例はこちら。
SharePointのオブジェクトを迅速かつ簡単にリストアできる「Veeam Explorer for SharePoint」。製品概要や新機能、エディション比較、特長はこちら。
投資対効果が高く安全で、エンタープライズにも対応している、Microsoft Azureのバックアップ専用製品「Veeam Backup for Microsoft Azure」。製品概要や成功事例などはこちら。