


The Veeam Hardened Repository is Veeam’s native solution to provide trusted immutability for backups of Veeam Backup & Replication on a Linux server. By supporting generic Linux servers, Veeam ensures that customers always have a choice about their hardware without vendor lock-in. Veeam also allows customers to use their trusted Linux distribution (Ubuntu, Red Hat, SUSE) instead of being forced to use a “custom Veeam Linux”.

Hardened Repositories help to ensure immutability for Veeam backups while meeting the 3-2-1 rule and combining Hardened Repositories with other immutable options like object lock on object storage or WORM tapes. This blog post will show how to select and prepare the environment for a physical server that will later be used as Hardened Repository. Future blog posts will cover topics such as preparation and planning, securing a Linux system and integrating into Veeam Backup & Replication
For those who are impatient, use (high-density) servers with internal disks. That approach scales linearly, because with each new Hardened Repository node, there is more CPU, RAM, RAID, network, disk space and IO performance. A rack full of high-density servers give around 8 PB native capacity. With Veeam native data reduction plus XFS space saving (block cloning), that can be up to 100 PB logical data in one rack with a backup speed up to 420 TiB/h.
If you have a small environment, don’t worry. Start with two rack units, 12 data disks and two disks for the operating system.
The network
Networking is a key factor in ensuring the Hardened Repository can help achieve recovery point objectives (RPO, how much data maximum can be lost) and recovery time objectives (RTO, how much time a restore would take). In a world of “incremental forever” backups, the network is sometimes forgotten, because of the low bandwidth requirements of the “incremental forever” approach. The recommendation is to design for a “full restore” scenario. Take your preferred calculation tool to estimate the bandwidth by matching it with your restore requirements.
A few examples of how long it takes to copy 10 TB data over different network speeds:
- 1 Gbit/s 22h 45min
- 10 Gbit/s 2h 15min
- 20 Gbit/s 1h 8min
- 40 Gbit/s 34min
- 100 Gbit/s less than 14min
100 Gbit/s is realistically the fastest that customers today put in a repository server. HPE has shown in 2021 with their Apollo 4510 server, that such speeds are achievable with a single server.
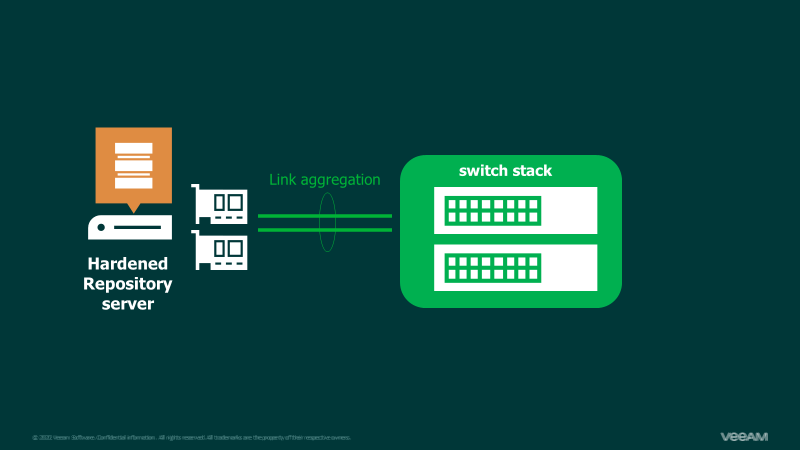
But it’s not only bandwidth. It’s also about redundancy. If there is only one network cable to the switch infrastructure, then this means a single point of failure. It is recommended to have a redundant network connection for the Hardened Repository. Depending on the network capabilities you have, that could be active/active links with load balancing (e.g. LACP/802.3ad) or a simple active/passive scenario.
Although Linux can easily be configured with VLAN tags, the KISS principle requires using untagged switchports. That means, one configures the IP addresses directly without any VLANs in Linux. The smallest redundant configuration for today would be 2X 10 Gbit/s connections to two switches/a switch stack (depending on our network environment).
To receive Linux security updates, there needs to be access to the Linux distribution security update servers.
For simplicity, we allow HTTP internet access outgoing on the firewall to obtain security updates. We only allow connections to the update servers of the Linux distribution of choice — not the whole internet. The alternative would be setting up a mirror of your preferred Linux distribution to get updates and software from there.
Finding the right server vendor and model
From Veeam’s side, the recommendation is to use a server with internal disks as a Hardened Repository. Internal disks are recommended because that eliminates the risk that an attacker could get access to the storage system and delete everything on the storage side. The server vendors sometimes have “Veeam backup server” models. These server models are optimized for the backup performance requirements and sticking to the vendor recommendations is a good idea.
If you have a preferred Linux distribution, then it makes sense to pick a model that is certified for that Linux distribution. Pre-tested configurations save a lot of time when working with Linux. The big brands usually have servers, that are compatible with the main Linux distributions such as Ubuntu, Red Hat (RHEL) and SUSE (SLES).
As I mentioned HPE before, Cisco has “Cisco validated designs” for Veeam for their S3260 and C240 series. Technically, every server vendor is fine from Veeam’s side, as long these essential requirements are met:
- RAID controller with battery powered write-back cache (or similar technology)
- RAID controllers with predictive failure analysis are strongly recommended
- With many disks (50+), multiple RAID controllers usually make sense, because of RAID controller speed limits (often capped around 2GByte/s)
- Separated disks for operating system and data
- SSDs strongly recommended for operating system
- Redundant power supply
- Redundant network with required link speed (see above)
CPU speed is relatively irrelevant, because Veeam is using the very fast LZ4 compression per default. Taking whatever the server vendor offers works fine. Many CPU cores help to run many tasks in parallel. 4 GB RAM per CPU core is the best practice recommendation. If you decide for 2X 16 CPU cores, then 128 GB RAM would be the perfect match. While that type of sizing might sound “over simplified”, it’s been working fine for years in our testing and live in production environments.
Basic server configuration
Before installing the Linux operating system, there are a few settings that must be configured. As mentioned before, operating systems and data are separated on different disks. On different RAID-sets, to be precise.
For the Linux operating system, a dedicated RAID 1 is used. 100 GB are more than enough. For the data disks, most customers go for RAID 6/60 for better price/value compared to RAID 10. RAID 5/50 or any other single-parity option forbids itself for safety reasons. The RAID 6/60 must be configured with at least one spare disk in “roaming configuration”. That means, the spare disk can replace any failed disk and becomes a production disk.
As the server is equipped with a proper RAID controller with write-back cache, the internal disk caches need to be configured to “disabled”. The recommended RAID stripe size is sometimes documented by the server vendor. If no information is available, then 128 or 256 KB are good values.
Enable UEFI secure boot, to prevent unsigned Linux kernel modules from being loaded.
How to get notified about broken disks?
One of the biggest challenges when hardening a server/Linux system is how to get notifications about failed disks. Every modern server has an “out of band” management (HPE iLO, Cisco CIMC, Dell iDRAC, Lenovo XCC etc.). They show the disk and RAID status and can notify per email about failed disks. This type of notification has the advantage that nothing needs to be configured on Linux later. If the management interface allows to configure multi-factor authentication, that’s good and should be used.

Keep in mind that multi-factor authentication does not protect against the many security issues that out of band management systems had in the past. Customers often avoid using them due to security reasons. If an attacker becomes an administrator on the out of band management, then they can delete everything of the Hardened Repository without touching the operating system. A compromise could be to put a firewall in front of the management port and only allow outgoing communication. That will allow to send email notifications if a disk fails. But an attacker cannot attack/log into the management interface because the firewall blocks all incoming connections.
The design could look like the example below:

If you decide to unplug the out of band management port completely, then the notifications about failed disks can be configured with software running on top of the Linux operating system. Server vendors often provide packages to view the status or even configure RAID from inside the operating system (e.g. http://downloads.linux.hpe.com/ ). These tools usually can send emails directly, or one can configure that with a script. Scripting and configuration of vendor specific tools are out of scope of this article.
Another option is physical or camera surveillance. If you are changing tapes every day and you can physically check the status LEDs of the Hardened Repository server, then this can be a workaround. I have also heard of customers who installed cameras pointing to the Hardened Repository server. The customer then regularly checks the LEDs of the disks via the camera.
Conclusion
Storing Veeam backups on immutable/on WORM compliant storage with Veeam is easy. Selecting the server hardware can be a challenge because there are so many vendors and options. One can limit the choices and speed up the decision by following these steps:
- Calculate the disk space you need on the repository
- Select your preferred (and supported by Veeam) Linux distribution (Ubuntu and RHEL are the most popular ones amongst Veeam customers)
- Check the hardware compatibility list of the Linux distribution to find a few vendors/server-models
- Talk to the server vendor to provide a solution, that fits your requirements
If there is no advice from the server vendor side, then go through the following points:
- If you use SSDs, then IOPS are no problem. If you use spinning disks, then keep IO limits in mind and not only the pure disk space. There is no strict rule how to calculate how much speed a disk can deliver, because it depends on the access pattern (sequential vs. random) Conservative calculations are between 10 and 50 MByte/s per disk in a RAID 60. With sequential reads, a 7k NL-SAS disk can deliver 80 MByte/s or even more (this includes all RAID overhead)
- 2X network card with the link speed you calculated above
- For CPU and RAM, there are formulas available in the best practice guide. In most cases one can save time by simply getting around two CPUs with 16-24 cores each and 128 GB RAM For the high-density servers with around 60 or more disks, most vendors put in 192–256 GB RAM.
Keep it simple: use servers with internal disks. That approach scales linearly, because with each new Hardened Repository node, there is more CPU, RAM, RAID, network, disk space and IO performance. It’s a simple and proven design.